With the free and open data access policy for satellite data, a large collection of Earth Observations(EO) data was made available to the public by many governments and space agencies. This abundance of remotely-sensed data has enhanced scientists in understanding and obtaining knowledge on environmental changes like climate change, urbanization, global mapping of forest changes, pollution, land cover changes, etc. One of the merits is that it has enabled time-series analysis and not just a comparison of a couple of images through time.
A manual search, download, and preprocessing of these data are almost impossible and thus emerged the concept of Earth Observation Data Cube (EODC) where they can handle the volume, variety, and velocity of data. Among different EODC implementations, Open Data Cube is one of the widely accepted and adopted solutions. The Open Data Cube provides a consolidated gridded data analysis environment for decades of analysis-ready earth observation satellites and related data from multiple satellites and other acquisition systems. According to the OpenDataCube website: “The objective of the ODC is to increase the impact of satellite data by providing an open and freely accessible exploitation tool, and to foster a community to develop, sustain, and grow the breadth and depth of applications.”
Open Data Cube is an efficiently indexed file system for satellite imagery, helps to innovate a better world, empowered by satellites by increasing the impact of EO satellite data. The technological solutions of the ODC platform remove the burden of data preparation, assists in acquiring quick results by making data queries easier and promotes an active and engaged global community of contributors. They also enable efficient time-series analysis.
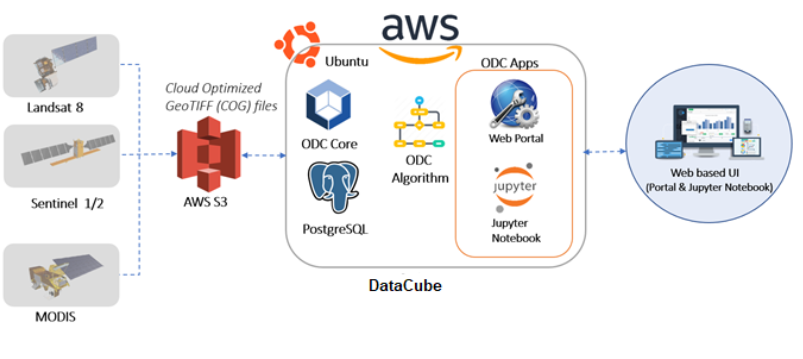
Technically, ODC is made up of three components – the satellite data, a database to store the indices of the data for faster retrieval, and software to view and analyze the data. The core of Open Data Cube is a set of python libraries and PostgreSQL database that enables you to work with geospatial raster data.
ODC is architected to categorize large amounts of Earth Observation data and provides a python-based API for high-performance querying and data access. The core of ODC acts as a connecting layer between satellite data and the user end of informed decision making. To make the ODC system aware of the existence of imagery there is a process called indexing. This helps ODC to track useful information in loading, searching, and analyzing the imagery. When it comes to the application level, ODC supports analysis like custom mosaics, water extent, water quality, coastal change, fractional cover, urbanization, NDVI anomaly, landslide risk, spectral indices, etc. The analysis outputs are delivered using jupyter notebook and web interfaces. The web user interface allows you to select the desired area and instantly hand over the analysis results in the form of plots, maps, or graphs.
The Swiss Data Cube is one of the first adopters of the Data cube system and the goal is to establish operational cubes in 20 countries by 2022. Currently, there are more than 4 operational Data Cubes around the globe, almost 11 in development and many other countries with expressed interest.
TA has also utilized this platform for some of its projects. Data from the ODC platform were used in jupyter notebooks for analyzing various themes related to cloud cover, land change, vegetation indices, water cover analysis, etc. We have been working with one of our clients in implementing an Open Data Cube instance for a specific region in the US. We have also been working on an ODC instance on Kerala – analyzing the floods that recently ravaged the Southern Indian state, which we have discussed in detail in one of our previous blogs.
If you are someone who is seeking support in implementing a similar instance/project, feel free to contact us…