

Overview
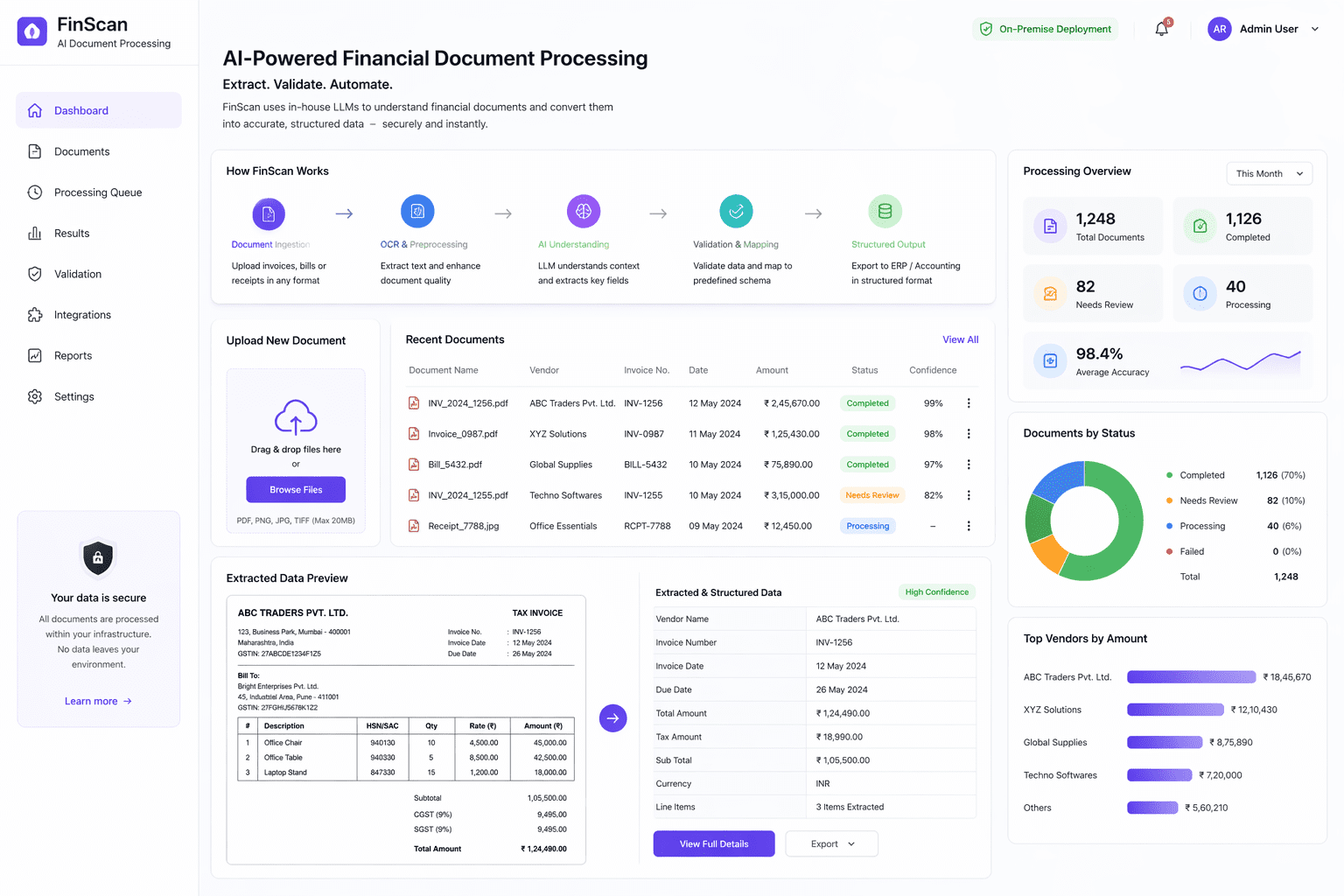
Financial data of organizations is often scattered across invoices, proposals, bills, receipts, etc., making it extremely difficult to interpret. We developed a financial document processing solution called FinScan, an AI-based, fully secure data extraction and analytics tool to automate the extraction and structuring of financial data from scattered documents. FinScan leverages in-house deployed open-source large language models (LLMs) to interpret unstructured or semi-structured financial documents and convert them into structured, system-ready data. Unlike traditional OCR-based tools, our solution understands contextual data, establishes relationships between parameters, and understands business semantics. FinScan operates within a fully secure environment, ensuring that sensitive financial data doesn’t leave the organization’s infrastructure.
Case
Organizations across industries typically deal with a lot of financial documents as part of their business operations. These documents could be of several categories, like accounting, auditing, resource procurement, compliance, etc. Filing, sorting, and analyzing these documents often involve:
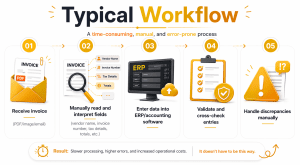
- Manually feeding data from scattered documents into ERP and accounting systems
- Exhaustive, time-consuming verification of extracted data
- High probability of human errors (typos, missing fields, incorrect mapping)
- Significant delays in data processing, especially for larger data sets.
- Compliance risks due to inaccurate or incomplete data capture
Challenges
Developing a secure AI-powered financial document processing engine poses certain technical and operational challenges:- Document Variability: For organizations, their financial data could be across several documents of different formats, layouts, and templates, varying with vendor standards. These documents could be in multiple languages, and the currencies could also vary. Scanned documents could also have quality issues like noise, skew, or low resolution.
- Complex Data Extraction: Extracting tabular data like line items, corresponding quantities, pricing, etc., and identifying key-value pairs, parameter relationships (tax breakdown vs total), and patterns.
- Contextual Understanding: Distinguishing similar fields (e.g., invoice date vs due date), mapping extracted values to a standardized schema, and handling missing or ambiguous data are other key challenges.
- Accuracy & Reliability: For financial data processing high precision is required, avoiding hallucinations from AI models and ensuring consistency across documents is critical
- Data Privacy & Compliance: Financial documents typically contain highly sensitive business data; cloud-based APIs may violate compliance requirements. A solution that operates fully on-premise or in a controlled deployment is a necessity in this scenario
- Scalability: Processing large volumes of financial data in real-time or batch mode, while maintaining platform performance and without compromising accuracy, is another key operational challenge.
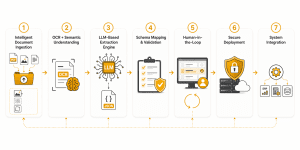
Solution
FinScan overcomes these challenges through a multi-layered AI-driven architecture:- Intelligent Document Ingestion: FinScan supports various document formats, including PDFs, scanned images, and digital invoices. The platform also enhances quality by carrying out pre-processing techniques such as image enhancement, noise reduction, skew correction, etc.
- OCR + Semantic Understanding: It leverages Optical Character Recognition (OCR) to convert scanned physical documents into editable, searchable, and machine-readable text data. This is combined with LLM-based context interpretation capabilities to map out relationships and patterns.
- LLM-Based Extraction Engine: FinScan operates fully offline by using in-house deployed open-source LLMs. It can understand document structures irrespective of the file format and extract key fields such as vendor details, invoice number, dates (invoice, due), line items, tax breakdown, total amount, etc. It then converts this data into structured JSON output to make it system-friendly.
- Schema Mapping & Validation: Maps extracted data into predefined, ERP-ready formats. It also validates the data by checking totals against line items, standardizing date formats, and ensuring all mandatory fields are present.
- Human-in-the-Loop: In scenarios where the system has low confidence in the extracted data, the UI enables human review and correction. The tool has a continuous feedback loop in place to improve model performance.
- Secure Deployment: The platform could be deployed in a private cloud environment, or it can operate fully on-premises, ensuring 100% data security. With no external API calls, the organization’s financial data remains private without breach of compliance. This is of critical importance to industries with strict regulatory requirements like finance, healthcare, etc.
- System Integration: FinScan can integrate seamlessly with existing ERP systems, accounting software, data warehouses, and more.
Impact
- 80-90% reduction in manual data entry efforts.
- 100% data privacy and adherence to compliance standards
- Faster invoice processing
- Improved accuracy by reducing human error
- Scalability with reduced operational overhead by minimizing manual effort
- Consistent, structured data for better decision making